My AI Learning Notes: Breaking Down Transformers, Vector Search, and FaceID
Have you ever wondered how your phone’s FaceID instantly recognizes you, even if you’re wearing glasses, in a dark room, or looking at a weird angle? Or how Google magically knows whether you are searching for a financial bank or a river bank?
The magic isn’t a black box. It’s a beautifully orchestrated system of math, data vectors, and architecture.
If you have 5 minutes, you’re about to learn exactly how modern AI reads, thinks, and compares the world , from individual words to the geometry of your face.
1. The Core Problem: Why AI Used to “Forget”
In the early days of Natural Language Processing (NLP), AI models read text exactly like humans do: one word at a time, from left to right.
There was a massive flaw with this approach. By the time the AI finished reading a long paragraph, it would completely “forget” what it read at the very beginning.
Then came Google. In 2017, they introduced a groundbreaking architecture that changed everything: The Transformer.
What is Self-Attention?
Instead of reading word-by-word, Transformers look at an entire sentence all at once. To do this without losing context, they use a mathematical mechanism called Self-Attention. Think of it as a relationship map that scores how much attention every single word should pay to every other word in a sentence.
Take this sentence:
“The bank of the river is muddy.”
Thanks to self-attention, the model looks at the word “bank” and instantly calculates its relationship to “river” and “muddy”. It assigns a high relationship score between them, realizing: “Ah, this ‘bank’ means land near water, not a financial institution!”
The Mathematics: Queries, Keys, and Values
To calculate these relationship maps, the model generates three vectors (lists of numbers) for every single word:
- Query (Q): “What am I looking for?”
- Key (K): “What information do I contain?”
- Value (V): “What actual content do I provide if we match?”
The model mathematically multiplies the Query of one word with the Key of every other word (Q * K). This score determines exactly how much of the Value (V) it should take from each word to build its final understanding.
2. Transformers Under the Hood: Encoders vs. Decoders
A standard Transformer is split into two powerhouses: the Encoder and the Decoder.
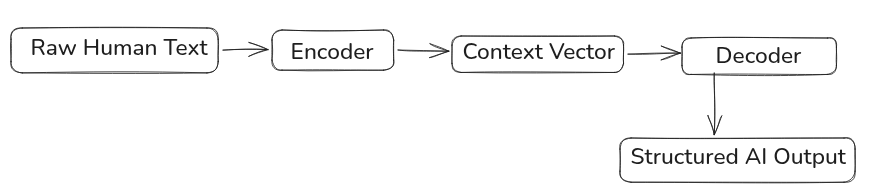
The Encoder (The Translator)
The Encoder’s job is to take raw, human-readable text (e.g., "Hello World") and compress its meaning into a high-dimensional mathematical map called a Context Vector or Hidden State (e.g., [0.823, 0.231, 0.561]). It looks at every word, maps their relationships using self-attention, and turns pure language into pure math.
The Decoder (The Storyteller)
The Decoder does the exact opposite. It takes those dense mathematical numbers, looks at what the Encoder mapped out, and predicts the next most logical word, one by one, translating the math back into a structured human response.
3. BERT vs. SBERT: Word Specialists vs. World-Class Librarians
BERT: The Word Specialist
BERT (Bidirectional Encoder Representations from Transformers) is an encoder-only model. It reads full sentences bidirectionally (left and right simultaneously) to understand deep word context.
- How it learns: It is trained on Masked Language Modeling (MLM). Imagine feeding it the sentence: I live in Butwal and today the weather is [MASKED].
- Because BERT knows geography and context, it predicts the missing word. If it guesses wrong during training, the system adjusts its internal weights until it gets it right.
- The Catch: BERT is a word specialist. If you give it a 10-word sentence, it outputs 10 separate vectors — one for each word.
SBERT: The World-Class Librarian
If you want to compare how similar two entire sentences or books are, BERT becomes highly inefficient. Enter SBERT (Sentence-BERT).
SBERT is a fine-tuned version of BERT designed to map an entire sentence into a single point in a dense vector space. This allows software to measure the semantic similarity of two sentences using simple geometry — specifically, Cosine Similarity (measuring the angle between two vector arrows).
4. The Pooling Layer: Condensing Information
How do we go from BERT’s 10 different word vectors down to SBERT’s single sentence vector? We use a Pooling Layer right on top of the encoder.
Imagine you have a sentence with 10 words. Each word gets a vector of 768 dimensions. The pooling layer compresses those 10 vectors into one single 768-dimensional vector that summarizes the entire sentence.
There are three main ways to do this:
- Mean Pooling: It adds all 10 vectors together and divides by 10 (sum(vectors) / count). It finds the mathematical average of the sentence's meaning. SBERT uses this because it yields superior accuracy for similarity searches.
- Max Pooling: The model scans the dimensions and pulls out only the highest, most dominant values (e.g., grabbing a highly stressed sentiment value while ignoring neutral ones).
- CLS-Pooling: BERT places a special classification token ([CLS]) at the very beginning of every sentence. Some systems just grab that token's vector and throw away the rest. While fast, research shows it isn’t great for deep similarity searches.
5. Production AI: Bi-Encoders vs. Cross-Encoders
When searching through millions of files in the real world, engineering teams combine two strategies to balance extreme speed with extreme accuracy.
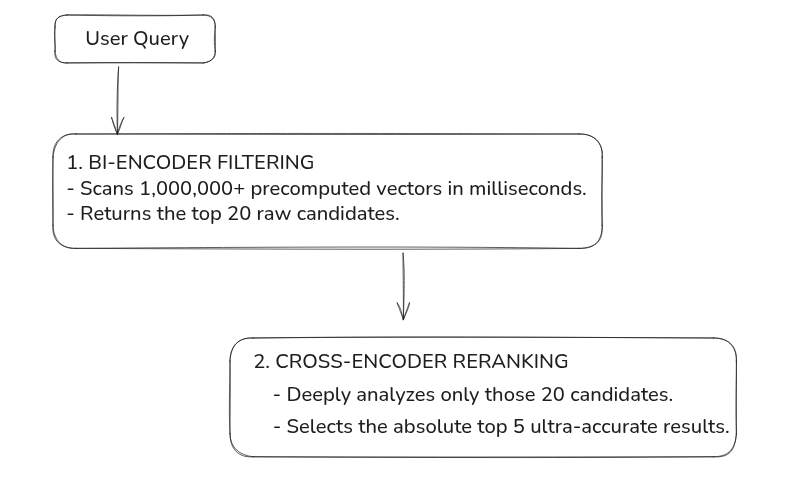
Bi-Encoders (The Speed Demons)
A Bi-Encoder processes your query into a vector independently of the documents.
- How it works: You pre-calculate and save the vectors for 1,000,000 documents in a Vector Database. When a user asks a question, the model runs exactly once to vectorise the query.
- The Verdict: Incredibly fast, but misses subtle deep-context connections between the query and the text.
Cross-Encoders (The Perfectionists)
A Cross-Encoder does not look at sentences separately. It feeds both pieces of text into the transformer simultaneously: [CLS] Sentence A [SEP] Sentence B [SEP].
- How it works: Because of self-attention, it evaluates the relationships between both sentences at the exact same time.
- The Verdict: Highly accurate, but incredibly slow. To find the best match out of 1,000 documents, you have to run the massive model 1,000 separate times.
The Industry Standard Pipeline
To get the best of both worlds, industries use a two-stage retrieval pipeline:
6. Twin Networks & FaceID: How It Applies to You
This exact architecture of comparing mathematical vectors explains how your phone unlocks using FaceID via a setup called a Siamese Network.
A Siamese Network consists of two identical neural networks that share the exact same configuration and weights. Think of them as twins working in tandem to solve similarity problems.
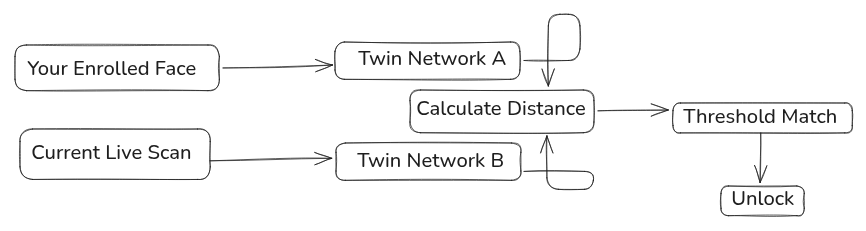
How FaceID Works Step-by-Step
- The Setup: When you first set up your phone, it scans your face from multiple angles. It does not save raw photos in your storage. Instead, it processes them through a neural network to generate a unique mathematical face coordinate (a vector like [0.998, 0.782, -0.112...]) and saves that math in secure, long-term storage.
- The Scan: The next time you glance at your phone to unlock it, the second twin network instantly turns your current face into a live vector.
- The Threshold: The system calculates the mathematical distance between your saved vector and your live vector. Because lighting and angles change, the vectors will never be a 100% identical match. The system uses a strict threshold constraint (e.g., if the similarity score is greater than 0.85, unlock the phone).
How Are These Models Trained? (Metric Learning & Triplet Loss)
To make sure a phone can tell the difference between you and a stranger, these networks are trained using a technique called Metric Learning utilizing a Triplet Loss function.
During training, the AI is continuously fed three items at once:
- Anchor: A photo of your face.
- Positive: Another photo of your face (from a different angle or lighting).
- Negative: A photo of a complete stranger.
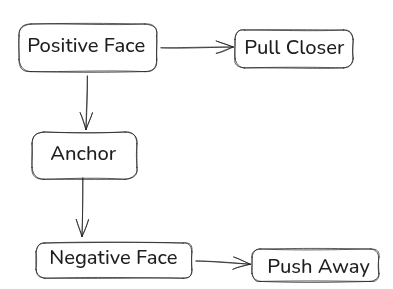
The mathematical objective is simple: minimize the distance between the Anchor and the Positive face, while maximizing the distance between the Anchor and the Negative face. If the model places a stranger’s face too close to yours in the vector space, it gets heavily penalized (“punished”) by the algorithm, forcing its internal weights to adjust.
Whether an AI is reading a complex legal document, searching for context-aware definitions, or verifying that your face matches your phone’s security registry, it is doing the exact same thing under the hood: converting human reality into mathematical vector spaces, mapping relationships via self-attention, and calculating distances. AI isn’t a mysterious, thinking consciousness, it is elegant geometry at scale.
If you came here reading all along please don't forget to follow me on my github. Thanks for reading :)